はじめに
デジタル情報が溢れる現代において、効率的なデータ管理とアクセスは重要な課題となっています。ここで注目されているのが「LlamaIndex」です。LlamaIndexは、高度な情報整理と検索機能を提供するツールで、ビジネスから教育まで、幅広い分野での活用が期待されています。データの構造化とアクセスの簡易化を実現することで、LlamaIndexは情報管理の新しい地平を切り開いています。
このツールは、特に情報の大量消費が日常となった現代において、その重要性が高まっています。多くの情報を迅速かつ効果的に処理し、必要なデータに素早くアクセスすることが、業務の効率化や知識獲得の鍵となるためです。
[blogcard url=”https://gpt-index.readthedocs.io/en/latest/index.html”]
今回はその中でもWebPageReaderを用いた、Webサイトの検索に特化した内容を紹介します。
WebPageReaderとは
LlamaIndexの機能の一つである「WebPageReader」は、ウェブページのコンテンツを効率的に読み込み、解析する機能です。この機能により、ユーザーは大量のウェブページから必要な情報を瞬時に抽出し、利用することができます。
リサーチや市場調査、学術研究や教育分野においても、関連情報の迅速な収集と整理が可能となり、効率的な学習や研究活動をサポートします。
[blogcard url=”https://gpt-index.readthedocs.io/en/latest/examples/data_connectors/WebPageDemo.html”]
WebPageReaderの実装サンプル
以下が実際のサンプルコードとなります。UIを使った方が見栄えが良いので、今回は爆速でWebアプリを動かすことができる「streamlit」も併せて使用しています。
当社のWebサイトを検索対象として設定しており、検索精度を上げるためにベクトル検索を実施します。
ソースコード全文
import streamlit as st
from llama_index import GPTVectorStoreIndex
from llama_index import ServiceContext
from llama_index import SimpleWebPageReader
from llama_index.callbacks import CallbackManager, LlamaDebugHandler
from llama_index.indices.list.base import ListRetrieverMode
URLs = [
"https://www.atd-net.com/",
"https://www.atd-net.com/company",
"https://www.atd-net.com/service_secure",
"https://www.atd-net.com/service_tech",
"https://www.atd-net.com/service_innovation"
]
llama_debug_handler = LlamaDebugHandler()
callback_manager = CallbackManager([llama_debug_handler])
service_context = ServiceContext.from_defaults(callback_manager=callback_manager)
metadata_fn = lambda fn: {"url": fn}
documents = SimpleWebPageReader(html_to_text=True, metadata_fn=metadata_fn).load_data(URLs)
vector_store_index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)
def search(prompt):
query_engine = vector_store_index.as_query_engine(
retriever_mode=ListRetrieverMode.EMBEDDING,
service_context=service_context
)
response = query_engine.query(prompt)
print("Response:" + response.response)
refer_url = ""
try:
refer_url = response.source_nodes[0].node.metadata["url"]
print("Refer URL: " + refer_url)
except:
pass
return response.response, refer_url
def clear_chat_history():
st.session_state.messages = []
def main():
st.title("🦜🔗Search AI demo app")
st.subheader("This chatbot trains on ATD InnoSolutions, Inc. website.")
st.button("Clear chat history", on_click=clear_chat_history)
# Initialize chat history
if "messages" not in st.session_state:
clear_chat_history()
# Display chat messages from history on app rerun
with st.spinner('Wait for it...'):
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# React to user input
if prompt := st.chat_input("What is up?"):
st.chat_message("user").markdown(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
with st.spinner('Wait for it...'):
response, quote_url = search(prompt)
content = f'''
:gray[{response}]
*Reference: [{quote_url}]({quote_url})*
'''
with st.chat_message("assistant"):
st.markdown(content)
st.session_state.messages.append({"role": "assistant", "content": content})
if __name__ == "__main__":
main()アプリケーションの実行
以下のコマンドを実行することでWebアプリが起動します。
streamlit run app.py --server.port=8051 --server.address=0.0.0.0localhost:8051にアクセスすると以下の画面が表示されます。
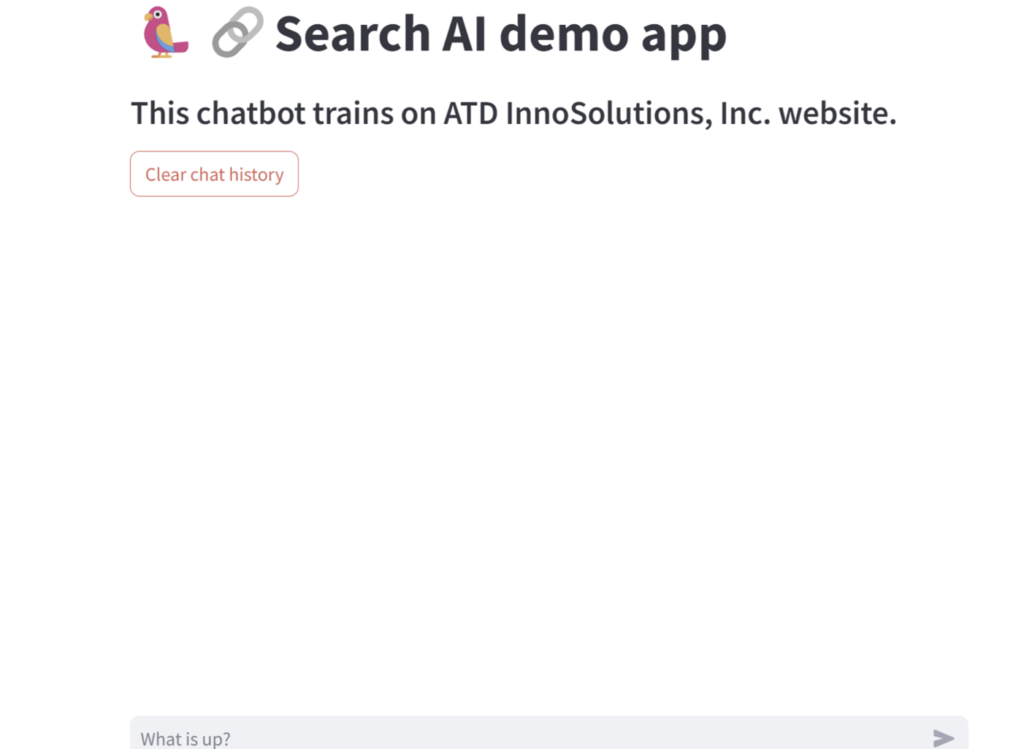
チャットに文字を入力すると、LlamaIndexで事前に読み込んでいたサイト一覧のベクトルデータから、検索処理を実行し、最も検索スコアの高い結果を回答します。
そして、参考にしたURLも同時に表示するようにしています。

コード解説
以下ざっくり分かりやすい言葉でコードを解説します。(分かりやすさ優先で記載しますので若干本来のニュアンスと異なる場合もあります。)
LlamaIndexの内部動作をデバッグするための出力や、コールバック関数によって処理された出力がコンソールに表示されます。(検索時間を取得するためなどに使用されます。)
llama_debug_handler = LlamaDebugHandler()
callback_manager = CallbackManager([llama_debug_handler])
service_context = ServiceContext.from_defaults(callback_manager=callback_manager)以下のように検索に要した時間を確認できるので便利です。
**********
Trace: query
|_CBEventType.QUERY -> 4.017421 seconds
|_CBEventType.RETRIEVE -> 0.260932 seconds
|_CBEventType.EMBEDDING -> 0.255718 seconds
|_CBEventType.SYNTHESIZE -> 3.756279 seconds
|_CBEventType.TEMPLATING -> 4.5e-05 seconds
|_CBEventType.LLM -> 3.750136 seconds
**********最初に定義したWebサイトのHTML情報から検索可能なテキスト形式でドキュメントとして保持します。
このときに、metadata_fn というパラメータを使うことで、メタデータを含むことができて後々回答の根拠になったサイト情報を取得することができます。
metadata_fn = lambda fn: {"url": fn}
documents = SimpleWebPageReader(html_to_text=True, metadata_fn=metadata_fn).load_data(URLs)metadata_fn パラメータは公式ドキュメントには記載ありませんが、以下公式GitHubにはしっかりとパラメータとして存在しています。
[blogcard url=”https://github.com/run-llama/llama_index/blob/main/llama_index/readers/web.py#L22C15-L22C15″]
サイトのドキュメント情報をベクトルデータに変換して保持します。ベクトル化するために、デフォルトではOpenAIの埋め込みベクトルモデルが使用されています。
vector_store_index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)入力された質問文を最初に埋め込みベクトルに変換して、保持していたベクトルデータに対して検索を実行します。
response.responseで回答結果の文字列を取得します。
query_engine = vector_store_index.as_query_engine(
retriever_mode=ListRetrieverMode.EMBEDDING,
service_context=service_context
)
response = query_engine.query(prompt)
print("Response:" + response.response)以下で回答を決定する際に参考にしたURL情報を取得します。
refer_url = response.source_nodes[0].node.metadata["url"]
print("Refer URL: " + refer_url)まとめ
いかがでしたでしょうか。
LlamaIndexのWebPageReaderを使うことで複数のWebサイトから簡単に情報を検索することが可能です。
当社、ATD InnoSolutionsでは生成AIを活用したサービス開発の実績が豊富に御座います。
開発相談、協業に関しては是非お気軽にお問合せください。